[On-Device AI Chatbot] 2편: 내 손안의 거대언어모델: 모바일용 SLM(Small Language Model) 선정 전략
- TecAce Software
- 2월 12일
- 3분 분량


내 손안의 거대언어모델
모바일용 SLM(Small Language Model) 선정 전략
1편에서는 클라우드 비용과 데이터 보안 문제를 해결하기 위해 '온디바이스 AI'가 필수적인 패러다임으로 자리 잡고 있음을 확인했습니다. 그렇다면 데이터센터의 거대한 GPU 랙에서나 돌아갈 법한 수백억, 수천억 개 파라미터의 거대 언어 모델(LLM)을 어떻게 스마트폰이라는 작은 기기 안에 넣을 수 있을까요?
그 해답은 바로 '소형 언어 모델(Small Language Model, SLM)'에 있습니다. 이번 2편에서는 2026년 현재 가장 주목받는 SLM들을 비교해 보고, TecAce가 실제 프로젝트를 위해 어떤 기준으로 모델을 테스트하고 최종 선정했는지 생생한 과정을 공유합니다.
2026년, SLM 생태계의 춘추전국시대
SLM은 일반적으로 100억 개(10B) 미만의 파라미터를 가지며, 스마트폰, 엣지 디바이스, 심지어 브라우저에서도 효율적으로 동작하도록 설계된 모델입니다. 단순히 크기만 줄인 것이 아니라, 고품질의 학습 데이터를 통해 기존 거대 모델에 필적하는 추론 능력을 갖추고 있습니다. 대표적인 모델들은 다음과 같습니다.
Llama 3.2 (Meta): 엣지 디바이스와 모바일 환경에 특화되어 설계된 모델입니다. 1B 및 3B 파라미터 버전이 있으며, 특히 3B 모델은 128K의 긴 컨텍스트 윈도우를 지원하면서도 도구 호출(Tool calling) 및 요약 작업에 매우 뛰어납니다.
Gemma 3 & Gemma 2 (Google): Google의 Gemini 기술을 기반으로 한 개방형 모델입니다. 2B~4B 파라미터 모델은 스마트폰 최적화가 잘 되어 있으며, 특히 Android 및 MediaPipe 생태계와의 통합이 매우 매끄럽습니다.
Phi-4-mini (Microsoft): 3.8B 파라미터 크기임에도 MMLU(대규모 다중 작업 언어 이해) 벤치마크에서 67.3%를 기록하며 매우 뛰어난 추론 및 코딩 능력을 보여줍니다.
Qwen 3 (Alibaba): 0.6B부터 다양한 크기를 제공하며, 4B 모델의 경우 10배 이상 큰 모델과 맞먹는 성능을 보일 만큼 최적화가 뛰어납니다.
이러한 모델들은 INT4(4비트) 등으로 양자화(Quantization)할 경우 약 2~3GB의 RAM만으로도 스마트폰에서 충분히 구동이 가능합니다.
TecAce의 온디바이스 모델 선정 기준
TecAce의 목표는 안드로이드(Android) 앱 내에서 완벽히 오프라인으로 동작하며, RAG(검색 증강 생성)를 통해 사내 문서를 기반으로 정확히 답변하는 챗봇을 만드는 것이었습니다. 이를 위해 다음과 같은 세 가지 주요 기준을 세웠습니다.
메모리 및 NPU 호환성: 안드로이드 OS 구동에 필요한 메모리를 제외하고, 앱이 사용할 수 있는 가용 RAM(보통 3~4GB 내외)에 모델이 적재되어야 합니다. 또한 모바일 NPU를 활용한 하드웨어 가속이 원활해야 합니다.
초당 토큰 생성 속도 (TPS): 자연스러운 대화를 위해 최소 20~50 TPS(Tokens Per Second)의 속도가 필요합니다. 사람이 읽는 속도에 맞춰 끊김 없는 텍스트 스트리밍이 필수적입니다.
프레임워크 생태계 (MediaPipe 연동): 안드로이드 네이티브 앱 개발을 위해 Google의 MediaPipe 프레임워크와 가장 안정적으로 연동되는 모델 구조가 필요했습니다.
TecAce Chatbot Test Matrix: 실제 기기(Galaxy S25 FE) 테스트 결과
TecAce 개발 팀은 위 기준을 바탕으로, Galaxy S25 FE 기기에서 모델 성능을 직접 측정하기 위한 Chatbot Test Matrix를 구축했습니다. 최종적으로 안드로이드 및 MediaPipe와의 호환성이 가장 뛰어난 Gemma-2b-it-int4 (20억 파라미터, 4비트 양자화 적용) 모델을 타겟으로 강도 높은 테스트를 진행했습니다.

추론 하이퍼파라미터(Hyperparameter)가 성능에 미치는 영향 분석 모델의 응답 속도와 품질의 최적점을 찾기 위해 파라미터별 성능 임팩트를 측정했습니다.
max_tokens (영향도 80~80%): 모델이 생성해야 할 최대 토큰 수입니다. 텍스트가 길어질수록 응답 시간이 선형적으로 증가하여 성능에 가장 절대적인 영향을 미쳤습니다.
top_k (영향도 10~20%): 디코딩 시 다음 단어 후보군의 크기를 결정합니다. K값이 커질수록 소프트맥스 연산이 늘어나 속도가 미세하게 저하되었습니다.
top_p (영향도 5~10%): 누적 확률 기반 샘플링으로, 값이 클수록 연산할 토큰이 많아져 속도가 약간 느려졌습니다.
temperature (영향도 <1%): 확률 분포의 평탄화 정도만 조절하므로, 연산 시간(Compute time)에는 거의 영향을 주지 않았습니다.
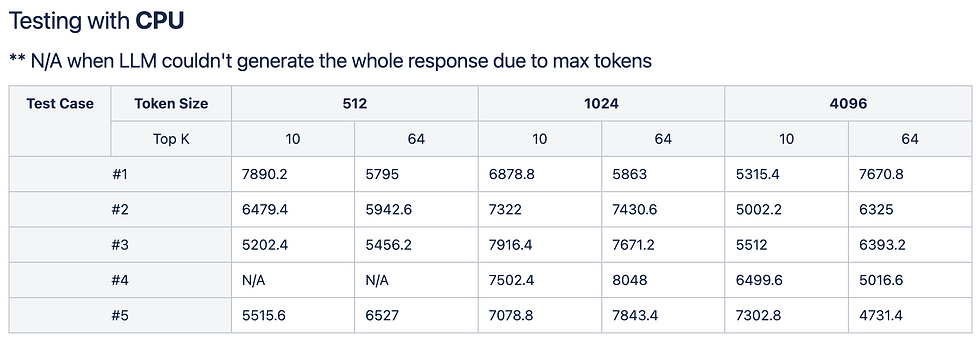
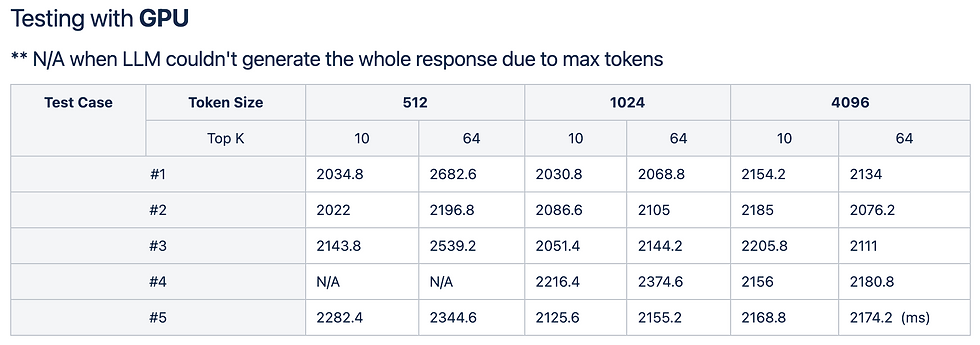
CPU vs GPU 구동 환경 비교
동일한 프롬프트로 CPU와 GPU 환경을 나누어 테스트를 진행했습니다.
CPU 환경에서는 초기 질문 처리 및 토큰 생성까지 수 초(5000~7800ms)의 긴 지연 시간이 발생했습니다.
반면 GPU 환경에서는 속도가 향상되었으나, 특정 하드웨어 자원 할당의 한계로 인해 설정된 max_tokens 분량의 전체 응답을 끝까지 생성하지 못하는(Out of Memory 등) 이슈가 발견되었습니다. 이는 제한된 모바일 자원 내에서 LLM을 구동할 때 겪는 전형적인 엣지 케이스입니다.
결론: Gemma-2B와 최적화의 필요성

테스트 결과, Gemma-2B (INT4) 모델은 모바일 환경에서 텍스트를 처리하고 사내 문서(Context)를 이해하는 데 충분한 지능을 보여주면서도 안드로이드 생태계(MediaPipe) 구축에 가장 적합한 모델로 최종 선정되었습니다.
하지만 CPU 환경에서의 응답 지연과 GPU 환경에서의 메모리 제약 이슈는, 모델을 단순히 기기에 올린다고 끝이 아니라는 것을 명확히 보여주었습니다. 진정한 '온디바이스 AI'를 구현하기 위해서는 하드웨어 가속기를 극한으로 쥐어짜는 기술적 다이어트가 필요합니다.
이어지는 [3편] 모바일 AI의 핵심 기술: 양자화(Quantization)와 NPU 최적화에서는 무거운 LLM을 스마트폰에 맞게 압축하는 양자화 기술의 원리와, 배터리를 절약하면서도 답변 속도를 끌어올리기 위한 모바일 NPU 최적화 적용 과정을 상세히 파헤쳐 보겠습니다.





댓글