Giant Language Models in the Palm of Your Hand: Mobile SLM Selection Strategy 2/10
- TecAce Software
- Feb 17
- 4 min read


Giant Language Models in the Palm of Your Hand
Mobile SLM Selection Strategy
In Part 1, we explored how "On-Device AI" is becoming an essential paradigm for solving cloud cost and data security issues. But how can we fit massive Large Language Models (LLMs) with tens or hundreds of billions of parameters—which typically run on massive GPU racks in data centers—into a small smartphone?
The answer lies in Small Language Models (SLMs). In Part 2, we will compare the most notable SLMs as of 2026 and share the vivid details of the criteria TecAce used to test and select the final model for our project.
2026: The Golden Age of the SLM Ecosystem
SLMs are generally models with fewer than 10 billion (10B) parameters, specifically designed to run efficiently on smartphones, edge devices, and even web browsers. Rather than simply reducing their size, they leverage high-quality training data to achieve reasoning capabilities comparable to their massive counterparts. Representative models include:
Llama 3.2 (Meta): A model heavily optimized for edge and mobile environments. Available in 1B and 3B parameter versions, it features a 128K context window and excels in tool calling and structured outputs.
Gemma 3 (Google): Built on Google's Gemini technology, this open-weight model family comes in sizes starting from 1B to 27B parameters. The 4B and below models are highly optimized for smartphones and integrate seamlessly with the Android and MediaPipe ecosystems.
Phi-4-mini (Microsoft): Despite having only 3.8B parameters, it achieves an impressive 67.3% on the MMLU (Massive Multitask Language Understanding) benchmark, showcasing outstanding reasoning and coding capabilities.
Qwen 3 (Alibaba): Ranging from 0.6B to various larger sizes, these models are exceptionally optimized; the 4B model, for instance, rivals models 10-18x its size in specific domains.
When compressed using INT4 (4-bit) quantization, these models can easily operate on smartphones using just about 2~3GB of RAM.
TecAce’s On-Device Model Selection Criteria
TecAce’s goal was to build a chatbot that operates entirely offline within an Android app and accurately answers questions based on internal company documents via RAG (Retrieval-Augmented Generation). To achieve this, we established three primary criteria:
Memory & NPU Compatibility: After accounting for the Android OS overhead, the model must fit into the app's available RAM (typically 3~4GB). It must also smoothly support hardware acceleration using mobile NPUs.
Tokens Per Second (TPS): For a natural conversational experience, a speed of at least 20~50 TPS is required. Seamless text streaming that matches human reading speed is essential.
Framework Ecosystem (MediaPipe Integration): To develop a native Android app, we needed a model structure that integrates most stably with Google's MediaPipe framework.
TecAce Chatbot Test Matrix: Real Device (Galaxy S25 FE) Test Results
Based on the above criteria, the TecAce development team built a Chatbot Test Matrix to measure model performance directly on a Galaxy S25 FE device. We ultimately targeted the Gemma-2b-it-int4 (2 billion parameters, 4-bit quantization applied) model—which offered the best compatibility with Android and MediaPipe—and conducted rigorous testing.

Impact of Inference Hyperparameters on Performance To find the sweet spot between response speed and quality, we measured the performance impact of each parameter:
- max_tokens (Impact: 80~80%): The primary performance factor. The model generates tokens sequentially, so latency grows roughly linearly as the maximum token count increases. This had the most absolute impact on performance.
- top_k (Impact: 10~20%): Determines the candidate set size during decoding. A larger K value requires more softmax operations, resulting in a slight slowdown.
- top_p (Impact: 5~10%): Nucleus sampling range. Expanding the probability pool evaluates more tokens, causing minor speed degradation.
- temperature (Impact: <1%): Only rescales the probability distribution. It had a negligible effect on actual compute time.
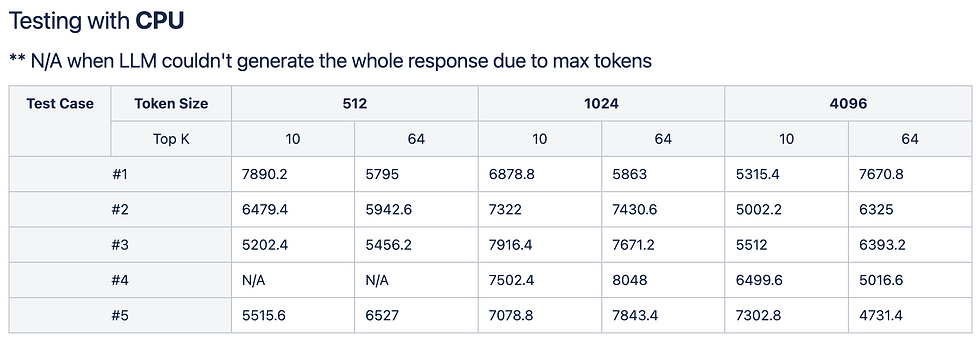
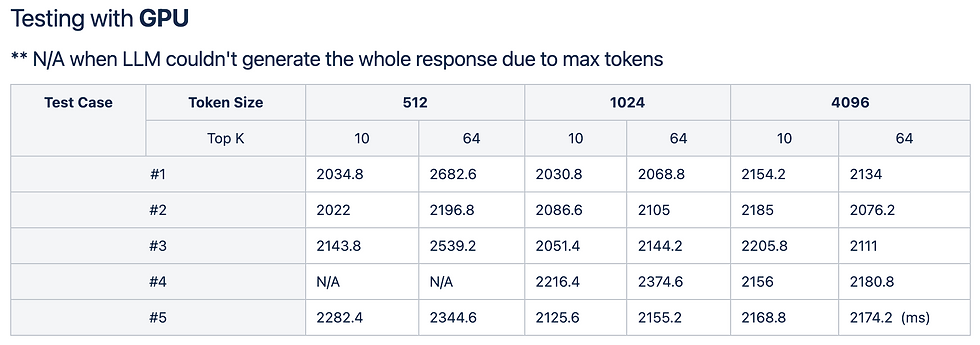
CPU vs. GPU Environment Comparison
- We tested the same prompts separately in CPU and GPU environments.
- In the CPU environment, we experienced a long initial delay of several seconds (5000~7800ms) before the question was processed and token generation began.
- In the GPU environment, processing speed improved. However, we discovered a critical edge case: due to hardware resource allocation limits, the LLM frequently failed to generate the entire response (e.g., throwing "N/A" results or Out of Memory errors) when hitting the allocated max_tokens limit. This is a typical challenge faced when running LLMs within restricted mobile resources.
Conclusion: Gemma-2B and the Need for Optimization

The test results demonstrated that the Gemma-2B (INT4) model possesses sufficient intelligence to process text and understand internal context (RAG) in a mobile environment, while also being the optimal choice for integration with the Android (MediaPipe) ecosystem. It was therefore selected as our final model.
However, the significant response delays in the CPU environment and the memory constraint issues in the GPU environment clearly proved that simply loading a model onto a device is not the finish line. To implement true "on-device AI," an extreme technical diet is necessary to squeeze every ounce of performance from the hardware accelerators.
In the upcoming [Part 3] Core Technologies of Mobile AI: Quantization and NPU Optimization, we will take a deep dive into the principles of quantization technology—which compresses heavy LLMs to fit into a smartphone—and the detailed NPU optimization process required to boost response speeds while preserving battery life.




Comments